
Overview
PDF by UnifyApps processes information by going through each page of the PDF and extracting the data.
This data can then be used in the rest of the automation using data pills.
.png&w=1080&q=75)
.png)
Use Case
Let’s say you want to collect all invoices received from Gmail and make a Google Sheet of key information.
We’ll use PDF by UnifyApps to extract pages one after another. We can then leverage Unify AI to split the text and obtain information essential to us, such as Name, Source, Amount, etc.
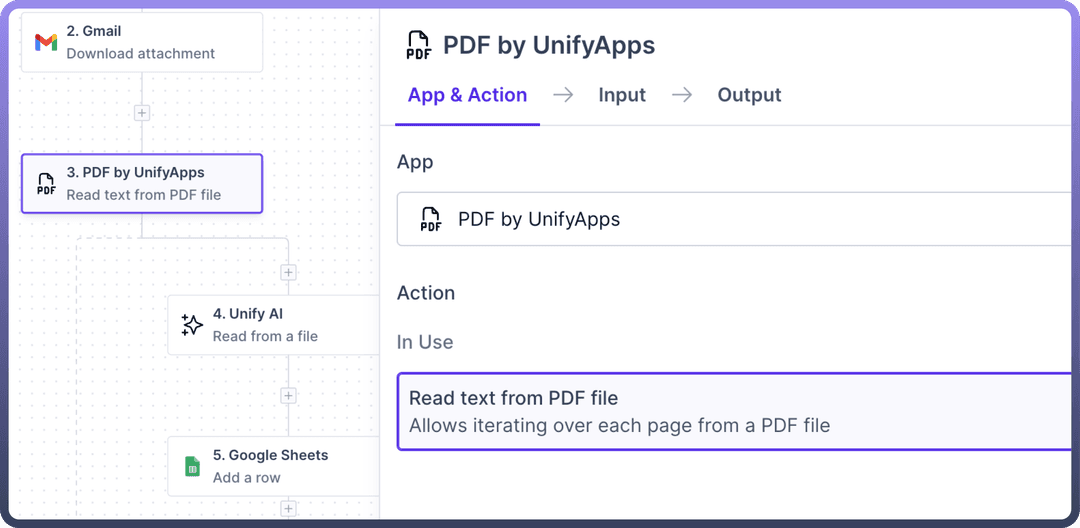
The data pill obtained from the PDF by UnifyApps can now be used to add a row to our Google Sheets file.
With the help of PDF by UnifyApps, this automation enables us to streamline the invoice collection process and maintain clean records.
How to Parse PDF?
We will add the
PDF by UnifyAppsnode, selectRead text from the PDF file, and proceed with providing input for the PDF field.The input can be either a
URL,base64 encoded string, or afile objectthat you would need to map from the upstream node.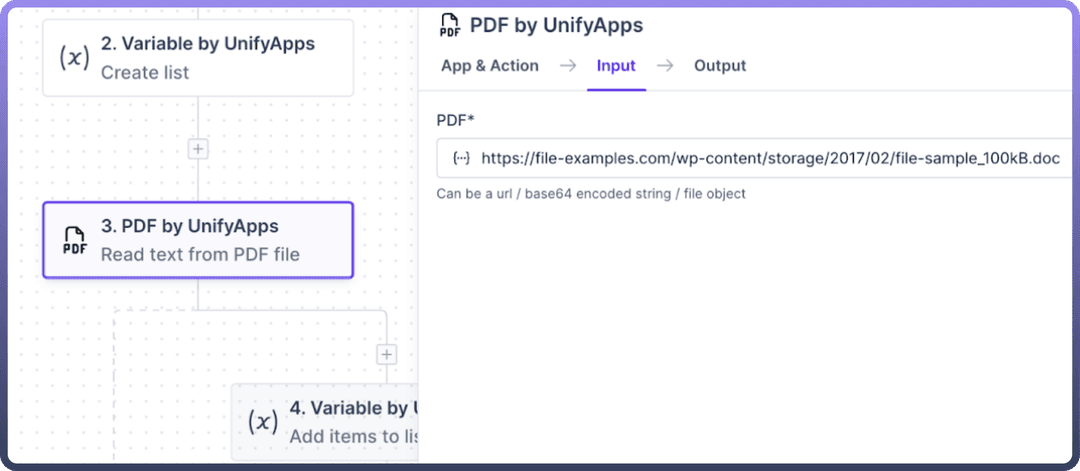
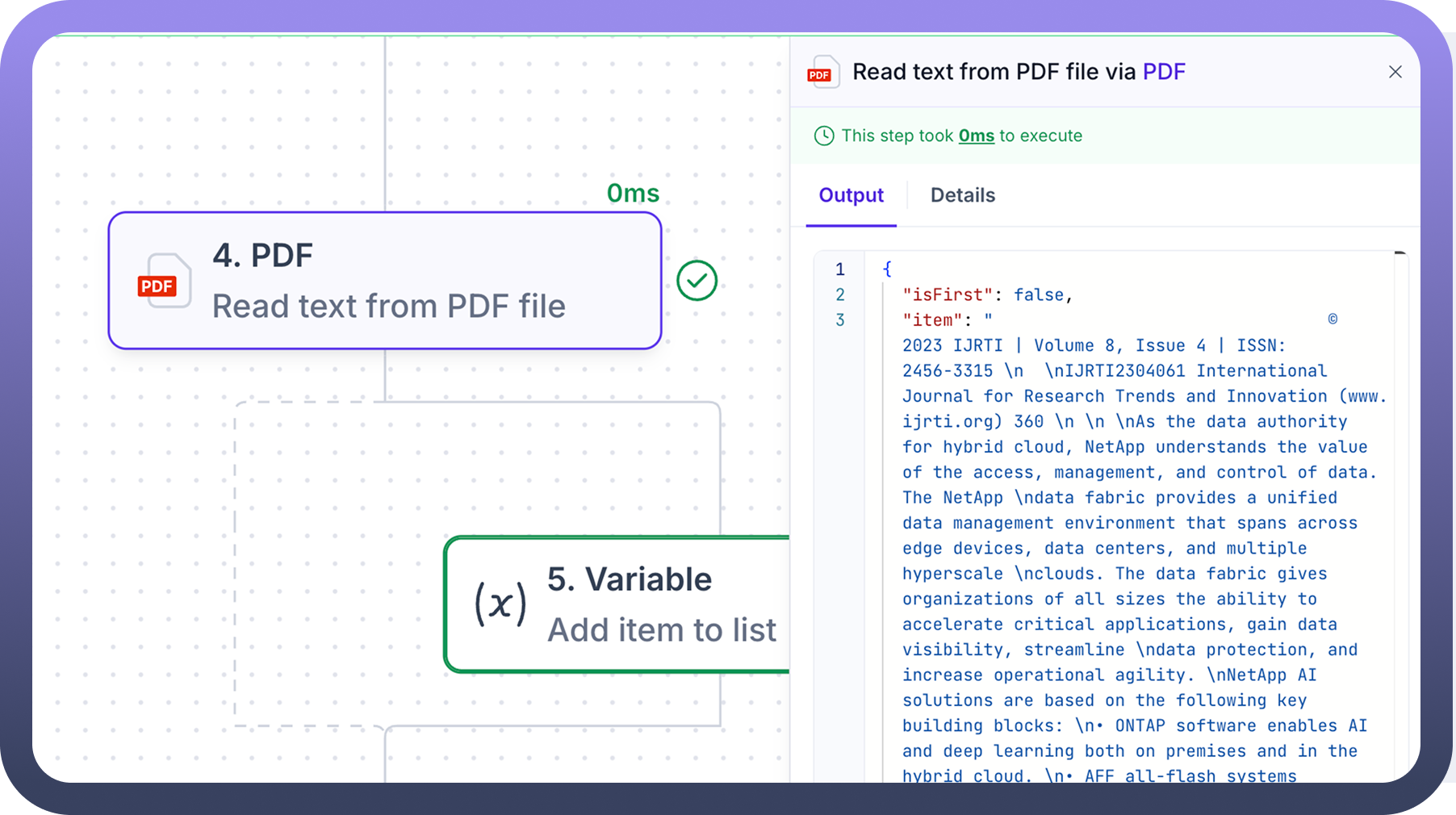
After setting the input parameter, add an
App & Actioninside the node's iteration. For example, here we are using Variable by UnifyApps to add pages to the list created earlier, one by one.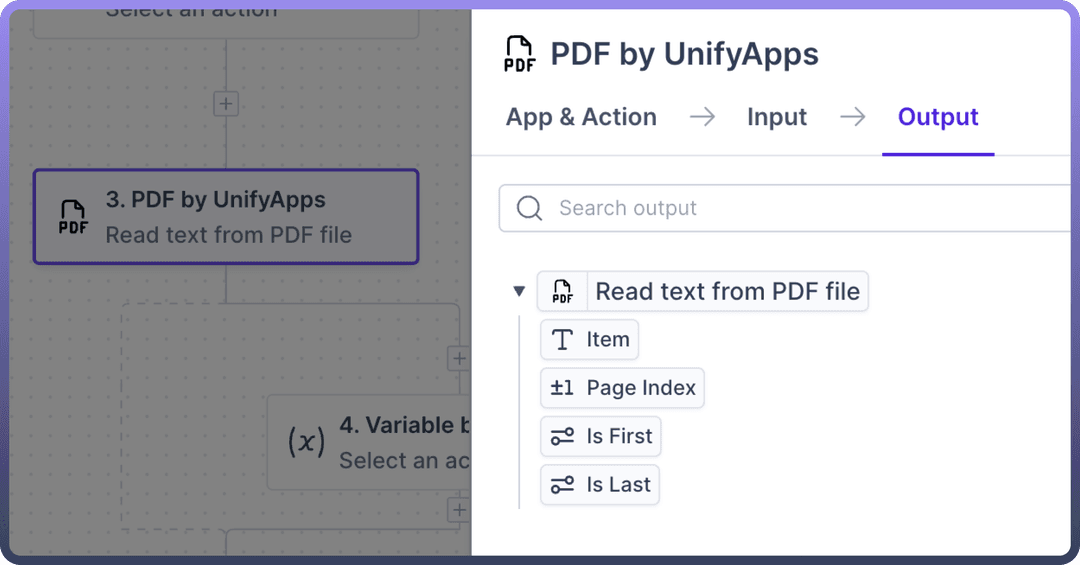
You can now extract the data from the PDF using the output datapill, which consists of:
an Item with the text from the page,
a Page Index denoting the page number,
Is First and Is Last, indicating if the current index is the first or the last page.


Note
Users must add a step after PDF by UnifyApps Node to complete the Automation. The Automation can’t be deployed without this step.